オライリーから出版されている入門自然言語処理をコツコツ読んでいる。
これからこの分野は確実に伸びるだろうし、何より夢がある。完全なリアルタイム自動翻訳、完全に会話の成り立つ人工知能、自分の心を癒してくれる心理カウンセラーのようなロボットなど。
今、自分に関係のある領域で言えばグーグルの検索アルゴリズムが進化するキーポイントとなる技術も自然言語処理だと思う。
もしグーグルのコンピュータがあるページに書かれている内容を完全に理解できるとすると、今みたいに被リンクに頼るアルゴリズムを使う必要性が全く無くなる。
検索ユーザーの意図を読み取って、その人の求めている情報が掲載されているページを検索結果に返せばいいだけ。
そのページがどこからリンクを貰っているとか、どれだけの数のリンクを貰っているかなんて完全に二次的なスコア付けに過ぎなくなる。
ということで自然言語処理という技術にすごく興味がある。
入門自然言語処理がいいのは、各章の終わりに演習問題が付いていることだと思う。本を読んで知識を入れるだけでも本当の理解には至らず、自分で考えて手を動かしたりして出力(アウトプット)してはじめて理解が深まる。
ただ、答えがどこにも書かれてない。仕方ないから他の人がブログなんかに書いてたりするのを参考にしながらやっています。
他にも同じような人がいるかもしれないので、僕も自分の解いた答えをブログに載せることにする。合っているかどうかは全く分からないし自信もありません。あくまでも参考という事にしていただいて間違いなどがあればコメント貰えると嬉しいです。
【第1章演習問題】
第1問
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from __future__ import division
def main():
print 12 / (4 + 1)
if __name__ == '__main__':
main()第2問
print 26 ** 100第3問
>>> ['Monty', 'Python'] * 20
['Monty', 'Python'] * 20
['Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python']第4問
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from nltk.book import *
def main():
print len(text2)
print len(set(text2))
if __name__ == '__main__':
main()
結果としてはtext2に含まれている単語の数は141,576個。重複を省くと6,833個。
第5問
---------------------------------------------------------------------------------
|ジャンル | トークン数 | 異なりアイテム数 | 語彙の多様性 |
---------------------------------------------------------------------------------
|ユーモア(humor) | 21,695| 5,017| 4.3|
---------------------------------------------------------------------------------
|ロマンス(romance) | 70,022| 8,452| 8.3|
---------------------------------------------------------------------------------トークン数/異なりアイテム数=語彙の多様性という計算式だからスコアが低い方が語彙は多様性に富んでいるという事。
もしトークン数が100で、現実的には不可能だろうけど全て異なる語彙を使えば異なりアイテム数も100になり語彙の多様性は1になるから。
したがって、ユーモアの方が語彙の多様性に富んでいる。
第6問
Sense and Sensibility(分別と多感)という本はtext2の事なのだがマリアンのスペルが分からないので検索した。
print [w for w in set(text2) if w.startswith('M')]これらが抽出されたけど、当てはまりそうなのはMarianneだけかな。
['Mansion', 'Magna', 'Me', 'Ma', 'Mr', 'My', 'ME', 'MY', 'Michaelmas', 'Midsummer', 'Monday', 'May', 'M', 'Many', 'MADAM', 'Madam', 'MIND', 'MAY', 'Mind', 'Mine', 'Misses', 'Mary', 'Marlborough', 'Mama', 'Most', 'Mrs', 'MUST', 'Music', 'MONTH', 'Must', 'Middletons', 'Misery', 'Margaret', 'Men', 'Mab', 'Mistress', 'Middleton', 'Mamma', 'Much', 'Martha', 'Marianne', 'Mid', 'Morton', 'Master', 'March', 'More', 'Mall', 'Miss', 'Months']
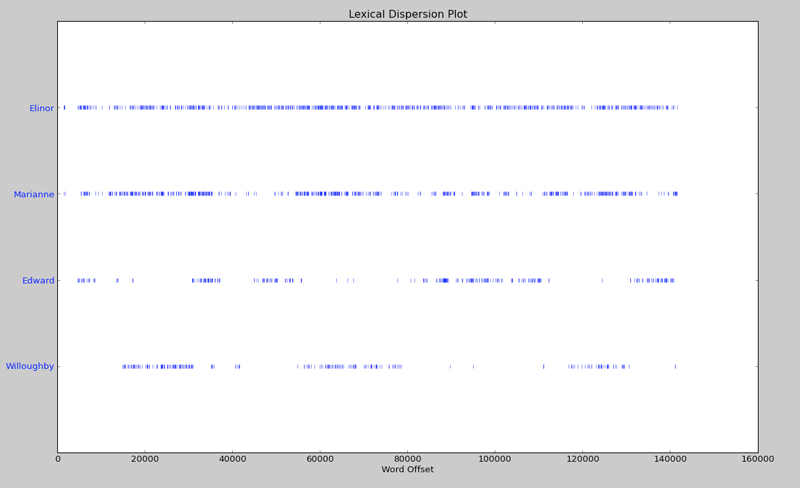
これら4人の名前を配列に入れてdispersion_plotメソッドに渡す。
print text2.dispersion_plot(['Elinor', 'Marianne', 'Edward', 'Willoughby'])以下のようなプロットが表示された。

この小説の中で男性と女性の演じる役割の違いを何か発見できるか?という問いがあるんだけど、男性はエドワードだけっぽい。
エリナとマリアンが主人公的な役割でエドワードとウィロビーが少し脇役的な役割というのはすぐに分かる。すぐに思いつくのはこれくらいなので女性が中心的な役割で男性が女性を引き立てるための脇役としての役割を果たしているという事にしておこう。
さらに、この情報から「カップルを特定せよ!」との質問がある。
一般的に考えて異性のカップルとするとエドワードを中心に残りの3人を考える事になる。
エドワードとウィロビーはほとんど同じ時間に登場していないのでおそらく違うだろう。
エリナかマリアンかはこの情報だけでは特定できないよね。
もし同性のカップルという事であれば万遍なく登場しているエリナとマリアンだろう。
エリナとマリアンがエドワードを巡って恋敵の状態になっていて、でも実はエドワードにはウィロビーという恋人がいるという設定もあり得る。
結論としてはこれだけでははっきりとは分からない。
【追記】Wikipediaでこの小説の事を調べてエリナとエドワードが恋人だという事が分かりました。ちなみにエリナとマリアンが姉妹でウィロビーも男性だそうです。Willoughbyで画像検索すると圧倒的に女性が多く出てきたんですけどね。
第7問
これは何も難しくない。
print text5.collocations()第8問
len(set(text4))という式の目的と意味は?
目的は、text4の中に含まれている単語の種類の数を調べる事。
set関数で2回以上登場する単語を1つにまとめてlen関数で単語の数を数える。
【入門自然言語処理解答(第1章)】