
文字実
この記事は、株式会社シグマ・デザイン社長の文字実が執筆しました。
入門自然言語処理の演習問題を解くシリーズ。

【第1問】
単語のリストを含んだ変数を作成しよう。その変数に対し、加算、乗算、添字、スライス表記、ソートを試してみよう。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
def main():
words = ['apple', 'orange', 'banana']
print words + ['grape']
print words * 3
print words[2]
print words[:2]
print sorted(words)
if __name__ == '__main__':
main()【第2問】
corpusモジュールを利用して、austen-persuasion.txtを調べてみよう。単語トークンはいくつかるか。また異なり語はいくつかるか。
単語トークンは98,171。異なり語は6,132。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import nltk
def main():
#print nltk.corpus.gutenberg.fileids()
persuasion = nltk.corpus.gutenberg.words('austen-persuasion.txt')
print len(persuasion)
print len(set(persuasion))
if __name__ == '__main__':
main()
【第3問】
NLTKのブラウンコーパスリーダーnltk.corpus.brown.words()とウェブテキストコーパスリーダーnltk.corpus.webtext.words()を利用して2つの異なるジャンルのテキストにいくつかアクセスしよう。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import nltk
def main():
#print nltk.corpus.brown.categories()
print nltk.corpus.brown.words(categories='news')
#print nltk.corpus.webtext.fileids()
print nltk.corpus.webtext.words(fileids='firefox.txt')
if __name__ == '__main__':
main()
【第4問】
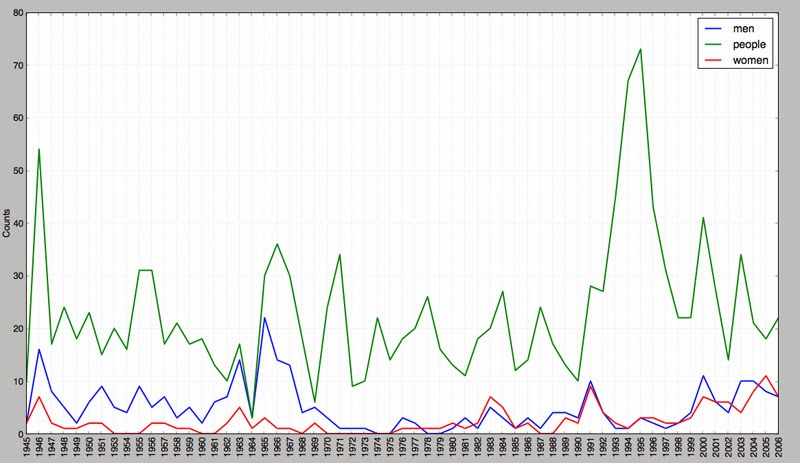
state_unionコーパスリーダーを用いてState of Union addressesのテキストを読み込もう。各ドキュメントについて、men、women、peopleの出現回数を数えよう。それらの単語の使われ方について、時代とともに変化があったかどうかを調べてみよう。
各ドキュメント内のmen, women, peopleの出現回数を出力。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import nltk
def main():
for file in nltk.corpus.state_union.fileids():
words = [w.lower() for w in nltk.corpus.state_union.words(fileids=file)]
freq = nltk.FreqDist(words)
print '【' + file + '】'
print 'men=%s, women=%s, people=%s' % (freq['men'],
freq['women'],
freq['people'])
if __name__ == '__main__':
main()
時代とともに変化があったかどうかを調べるためにグラフにする。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import nltk
def main():
cfd = nltk.ConditionalFreqDist(
(target, file[:4])
for file in nltk.corpus.state_union.fileids()
for w in nltk.corpus.state_union.words(file)
for target in ['men', 'women', 'people']
if w.lower().startswith(target))
print cfd.plot()
if __name__ == '__main__':
main()
このようなグラフが表示される。

【第5問】
いくつかの名詞について、ホロニムとメロニムの関係について調べる。ホロニムとメロニムの関係には3種類あるので、member_meronyms()、part_meronyms()、substance_meronyms()、member_holonyms()、part_holonyms()、substance_holonyms()を使う必要がある。
humanでやってみた。
#!/usr/bin/env python
#-*- coding: utf-8 -*-
from nltk.corpus import wordnet as wn
def main():
for synset in wn.synsets('human', wn.NOUN):
print synset.name + ':', synset.definition
print wn.synset('human.n.01').member_meronyms()
print wn.synset('human.n.01').part_meronyms()
print wn.synset('human.n.01').substance_meronyms()
print wn.synset('human.n.01').member_holonyms()
print wn.synset('human.n.01').part_holonyms()
print wn.synset('human.n.01').substance_holonyms()
if __name__ == '__main__':
main()